|
B站我想大家都熟悉吧,其实 B 站的爬虫网上一搜一大堆。不过纸上得来终觉浅,绝知此事要躬行,我码故我在。最终爬取到数据总量为 760万 条。 准备工作 首先打开 B 站,随便在首页找一个视频点击进去。常规操作,打开开发者工具。这次是目标是通过爬取 B 站提供的 api 来获取视频信息,不去解析网页,解析网页的速度太慢了而且容易被封 ip。 勾选 JS 选项,F5 刷新
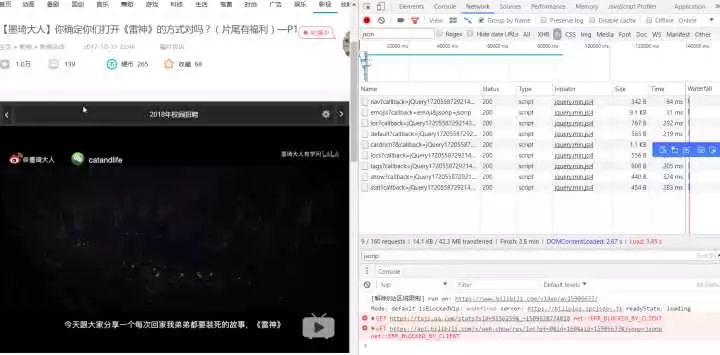
找到了 api 的地址
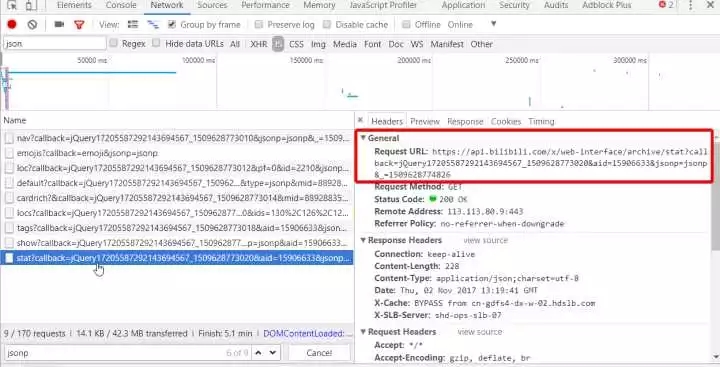
复制下来,去除没必要的内容,得到https://api.bilibili.com/x/web-i ... e/stat?aid=15906633 ,用浏览器打开,会得到如下的 json 数据
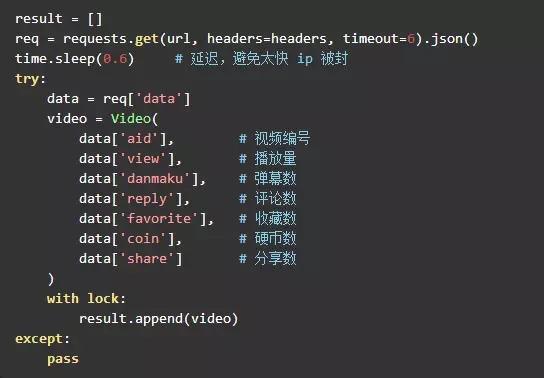
动手写码 好了,到这里代码就可以码起来了,通过 request 不断的迭代获取数据,为了让爬虫更高效,可以利用多线程。 核心代码
迭代爬取
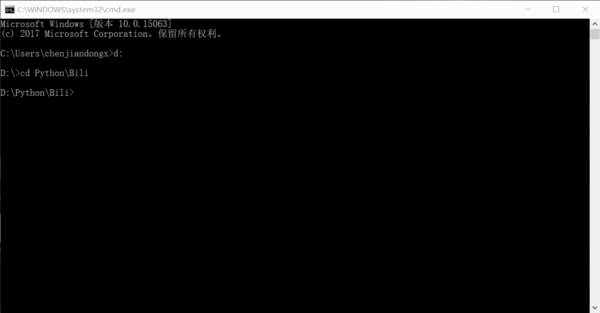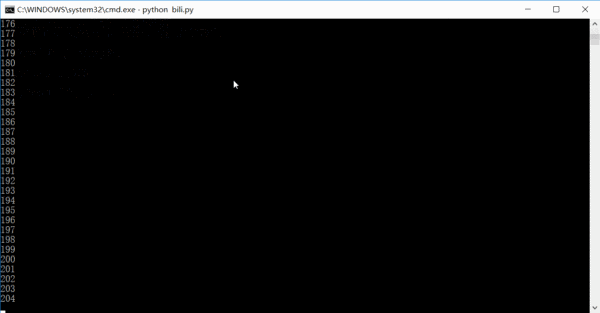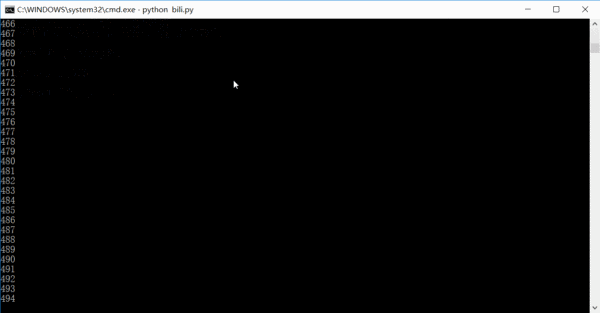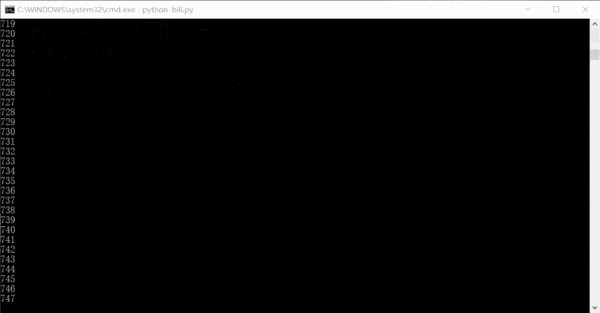
整个项目的最主要部分的代码也就是 20 行左右,挺简洁的。 运行的效果大概是这样的,数字是已经已经爬取了多少条链接,其实完全可以在一天或者两天内就把全站信息爬完的。
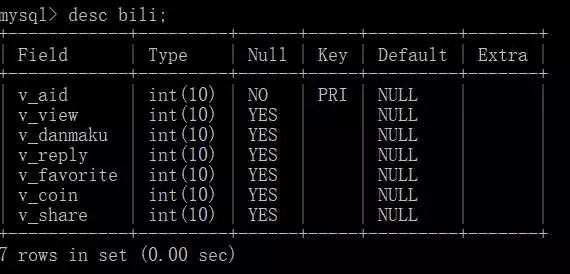
至于爬取后要怎么处理就看自己爱好了,我是先保存为 csv 文件,然后再汇总插入到数据库。 数据库表
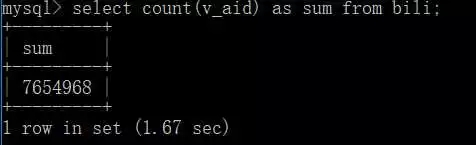
由于这些内容是我在几个月前爬取的,所以数据其实有些滞后了。 数据总量
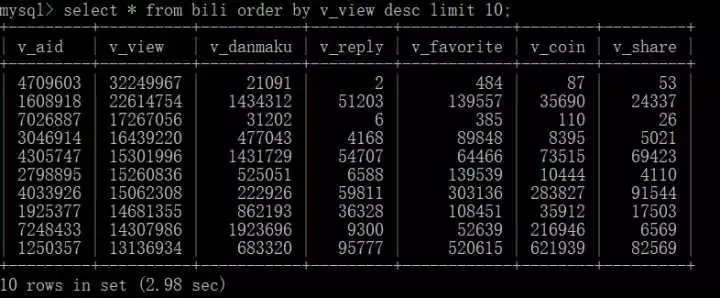
查询播放量前十的视频
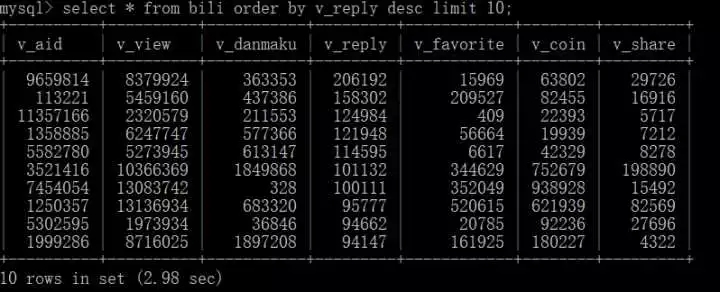
查询回复量前十的视频
| 

 简体中文
简体中文 英语
英语
 日语
日语
 韩语
韩语
 法语
法语
 西班牙语
西班牙语
 越南语
越南语
 泰语
泰语
 阿拉伯语
阿拉伯语
 俄语
俄语
 葡萄牙语
葡萄牙语
 德语
德语
 意大利语
意大利语
 希腊语
希腊语
 荷兰语
荷兰语
 波兰语
波兰语
 保加利亚语
保加利亚语
 爱沙尼亚语
爱沙尼亚语
 丹麦语
丹麦语
 芬兰语
芬兰语
 捷克语
捷克语
 罗马尼亚语
罗马尼亚语
 斯洛文尼亚语
斯洛文尼亚语
 瑞典语
瑞典语
 匈牙利语
匈牙利语
 繁体中文
繁体中文
 文言文
文言文




 发表于 2017-12-7 22:02:14
发表于 2017-12-7 22:02:14

 置顶卡
置顶卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶